
Artificial intelligence (AI) is rapidly transforming the world around us. AI models are being used to solve complex problems in a wide range of domains, from healthcare to finance to transportation. But how do AI models learn?
The answer is AI training! AI training is the process of teaching AI models to perform specific tasks by providing them with data. The more data an AI model is trained on, the better it will be able to perform the task.
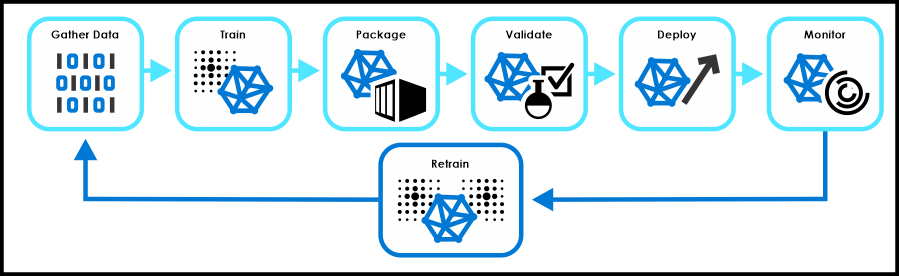
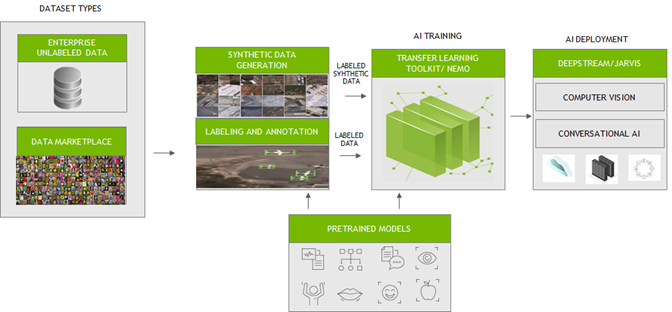
Different Types of AI Training Data
AI training data can be divided into 3 main categories:
- Labeled data: Labeled data is data that has been assigned a label or output. For example, a labeled dataset of images of cats and dogs could be used to train an AI model to recognize cats and dogs. Think of these data as a set of “flashcards” for AI.
- Unlabeled data: Unlabeled data is data that has not been assigned a label or output. For example, a dataset of unlabeled images could be used to train an AI model to cluster the images into different groups based on their visual features.
- Synthetic data: Synthetic data is data that is artificially generated. For example, a synthetic dataset of medical images could be used to train an AI model to diagnose diseases. The power of synthetic data can amplify AI training, creating a larger dataset of information to train them.
Data Preprocessing
Before AI training can begin, the data needs to be preprocessed. This involves cleaning the data, removing any errors or outliers, and transforming the data into a format that is compatible with the AI model.
Model Selection
Once the data has been preprocessed, the next step is to select an AI model for the task at hand. There are many different types of AI models available, each with its own strengths and weaknesses. Some common AI models include:
- Linear regression: Linear regression is a supervised learning model that is used to predict continuous values. For example, linear regression could be used to predict the price of a house based on its square footage and number of bedrooms.
- Logistic regression: Logistic regression is a supervised learning model that is used to predict binary values. For example, logistic regression could be used to predict whether a customer will churn or not based on their past purchase history.
- Decision trees: Decision trees are supervised learning models that are used to classify data. For example, a decision tree could be used to classify emails as spam or not spam based on the words contained in the email.
Hyperparameter Tuning
Once an AI model has been selected, the next step is to tune the hyperparameters of the model. Hyperparameters are parameters that control the training process of the model. For example, the learning rate and number of epochs are two common hyperparameters.
The goal of hyperparameter tuning is to find a set of hyperparameters that maximizes the performance of the model. Hyperparameter tuning can be a challenging task, but there are a number of automated hyperparameter tuning tools available.
Model Evaluation
Once the AI model has been trained, it is important to evaluate its performance on a held-out test set. This helps to ensure that the model is not overfitting the training data.
There are a number of different model evaluation metrics that can be used, such as accuracy, precision, recall, and F1 score. The best metric to use will depend on the specific task at hand.
Model Deployment
Once the AI model has been evaluated and found to be performing well, it can be deployed to production. This means making the model available so that it can be used to make predictions on new data.
There are a number of different ways to deploy AI models, such as using cloud-based services or on-premises servers. The best deployment method will depend on the specific needs of the organization.
Real-World Examples
AI training is used in a wide range of real-world applications, including:
- Image recognition: AI models trained on large datasets of images can be used to recognize objects and people in images. This technology is used in applications such as facial recognition, self-driving cars, and medical imaging.
- Natural language processing: AI models trained on large datasets of text can be used to understand and generate human language. This technology is used in applications such as machine translation, chatbots, and voice assistants.
- Recommendation systems: AI models trained on data about user preferences can be used to recommend products, movies, music, and other items to users. This technology is used by companies such as Netflix, Amazon, and Spotify.
Challenges in AI Training
One of the biggest challenges in AI training is bias. If the data used to train an AI model is biased, the AI model will also be biased. This can lead to problems such as racial discrimination in facial recognition systems and gender discrimination in hiring algorithms.
Conclusion
AI training is a complex and challenging process, but it is essential for the development of AI models that can be used to solve real-world problems. By understanding the different types of AI training data, the data preprocessing pipeline, and the model selection and evaluation process, we can develop AI models that are more powerful and versatile than ever before.
Leave a Reply